مقدمة في الذكاء الاصطناعي
يشكل الذكاء الاصطناعي (Artificial Intelligence) أحد أهم المجالات التقنية في عصرنا الحالي، حيث يهدف إلى محاكاة القدرات الذهنية البشرية وأنماط عملها through أنظمة حاسوبية مصممة للتفكير والتحليل بشكل يشبه العقل البشري. بدأ الذكاء الاصطناعي كمجال أكاديمي في الخمسينيات من القرن الماضي، وتطور عبر العقود ليشمل فروعاً متعددة وتطبيقات متنوعة تغطي مختلف جوانب الحياة الحديثة.
يتضمن الذكاء الاصطناعي إنشاء أنظمة قادرة على أداء مهام تتطلب عادةً ذكاءً بشرياً، مثل التعرف على الأنماط، فهم اللغة الطبيعية، اتخاذ القرارات، وحل المشكلات المعقدة. تعتمد هذه الأنظمة على خوارزميات متطورة وقواعد بيانات ضخمة لتحقيق أهدافها. يتميز الذكاء الاصطناعي بقدرته على التعلم من البيانات والتجارب السابقة، مما يمكنه من تحسين أدائه بشكل مستمر مع مرور الوقت وزيادة كمية البيانات المتاحة.
تنقسم أنظمة الذكاء الاصطناعي عموماً إلى نوعين رئيسيين: الذكاء الاصطناعي الضيق (Narrow AI) المصمم لأداء مهام محددة، والذكاء الاصطناعي العام (General AI) الذي يهدف إلى محاكاة الذكاء البشري الشامل في مختلف المجالات. بينما نمتلك حالياً تطبيقات متقدمة للذكاء الاصطناعي الضيق، يبقى الذكاء الاصطناعي العام هدفاً طويل المدى للبحث العلمي.
التطور التاريخي للذكاء الاصطناعي
مر مجال الذكاء الاصطناعي بعدة مراحل تطورية منذ نشأته، بدءاً من فترة الخمسينيات حين عقد أول مؤتمر أكاديمي حول الذكاء الاصطناعي في دارتموث عام 1956، والذي وضع الأسس النظرية للمجال. خلال هذه الفترة المبكرة، ركز الباحثون على حل المشكلات الرمزية ومحاكاة المنطق البشري من خلال أنظمة قائمة على القواعد.
في الثمانينيات والتسعينيات، شهد المجال تحولاً نحو الأساليب الإحصائية والتعلم الآلي، مع تزايد الاهتمام بالشبكات العصبية الاصطناعية. أدى التقدم في قوة الحوسبة وتوفر البيانات الكبيرة إلى ازدهار البحث في خوارزميات التعلم العميق في العقد الثاني من القرن الحادي والعشرين، مما أسفر عن تطبيقات ملموسة في مجالات مثل التعرف على الصور والصوت.
يشهد العقد الحالي تطوراً سريعاً في نماذج الذكاء الاصطناعي التوليدية كبيرة الحجم، التي تستطيع إنشاء محتوى نصي ومرئي وسمعي بدرجة عالية من الجودة والتماسك. هذا التقدم يفتح آفاقاً جديدة للتطبيقات但同时 يطرح تحديات أخلاقية وتنظيمية مهمة تحتاج إلى معالجة.
أنواع التعلم في الذكاء الاصطناعي
يمكن تصنيف خوارزميات الذكاء الاصطناعي حسب طريقة التعلم إلى ثلاثة أنواع رئيسية: التعلم تحت الإشراف (Supervised Learning)، والتعلم غير المشرف (Unsupervised Learning)، والتعلم التعزيزي (Reinforcement Learning). كل نوع من هذه الأنواع مناسب لمجموعة مختلفة من المشكلات والتطبيقات.
في التعلم تحت الإشراف، يتم تدريب النموذج على مجموعة بيانات تحتوي على المدخلات والمخرجات المرغوبة. الهدف هو تعلم دالة تربط المدخلات بالمخرجات بحيث يمكن توقع المخرجات لمدخلات جديدة. من التطبيقات الشائعة لهذا النوع: التصنيف (Classification) والانحدار (Regression). على سبيل المثال، يمكن تدريب نموذج للتعرف على البريد العشوائي باستخدام أمثلة على رسائل البريد الإلكتروني مصنفة مسبقاً كـ"spam" أو "not spam".
أما التعلم غير المشرف، فيتعامل مع بيانات غير مصنفة ولا تحتوي على مخرجات مرغوبة. الهدف هو اكتشاف الأنماط والهياكل الكامنة في البيانات. من التقنيات الشائعة في هذا النوع: التجميع (Clustering) وتقليل الأبعاد (Dimensionality Reduction). مثال على ذلك: تجميع العملاء حسب سلوك الشراء لتحديد شرائح السوق المختلفة.
التعلم التعزيزي يعتمد على فكرة وكيل (Agent) يتفاعل مع بيئة ويتعلم من خلال التجربة والخطأ بناءً على نظام المكافآت. الهدف هو تعلم سياسة (Policy)最优 تحقق أقصى قدر من المكافأة التراكمية على المدى الطويل. هذا النوع من التعلم فعال بشكل خاص في مجالات مثل الألعاب والروبوتات والتحكم في الأنظمة.
الشبكات العصبية الاصطناعية
تمثل الشبكات العصبية الاصطناعية (Artificial Neural Networks) أحد أهم نماذج الذكاء الاصطناعي، حيث تستوحي فكرتها من structure الدماغ البشري biological. تتكون هذه الشبكات من وحدات معالجة مترابطة تسمى الخلايا العصبية الاصطناعية (Artificial Neurons)، organized في طبقات متعددة.
تتألف الشبكة العصبية الأساسية من ثلاث طبقات: طبقة الإدخال (Input Layer) التي تستقبل البيانات، وطبقة hidden واحدة أو أكثر (Hidden Layers) التي تقوم بمعالجة البيانات، وطبقة الإخراج (Output Layer) التي تنتج النتيجة النهائية. كل connection بين الخلايا العصبية له وزن (Weight) يحدد قوته، وتقوم كل خلية عصبية بحساب weighted sum للمدخلات ثم تطبيق دالة تنشيط (Activation Function) لإنتاج مخرجها.
عملية تدريب الشبكة العصبية تتضمن ضبط الأوزان لتقليل الفرق بين المخرجات المتوقعة والمخرجات الفعلية. يتم ذلك عادةً باستخدام خوارزمية backpropagation بالاشتراك مع optimization algorithms مثل gradient descent. مع تقدم التدريب، تتعلم الشبكة تمثيلات متزايدة التعقيد للبيانات، مما يمكنها من حل مهام معقدة.
هناك أنواع متخصصة من الشبكات العصبية المناسبة لأنواع مختلفة من البيانات والمهام. الشبكات العصبية التلافيفية (Convolutional Neural Networks) مثالية لمعالجة البيانات ذات البنية الشبكية مثل الصور، بينما الشبكات العصبية المتكررة (Recurrent Neural Networks) مناسبة للبيانات المتسلسلة مثل النصوص والسلاسل الزمنية.
معالجة اللغة الطبيعية
معالجة اللغة الطبيعية (Natural Language Processing - NLP) هي فرع من فروع الذكاء الاصطناعي يركز على تفاعل الحاسوب مع اللغة البشرية. الهدف هو تمكين الآلات من فهم، تفسير، وتوليد اللغة البشرية بشكل ذي معنى. يشمل هذا المجال مجموعة wide من المهام مثل ترجمة الآلة، تحليل المشاعر، التعرف على الكيانات المسماة، والتلخيص التلقائي.
مرت معالجة اللغة الطبيعية بتحول جذري من الأساليب القائمة على القواعد إلى النماذج الإحصائية ثم إلى نماذج التعلم العميق. في السابق، اعتمدت الأنظمة على قواعد لغوية معقدة وقواميس كبيرة، ولكن هذه الأساليب كانت limited وغير قابلة للتطوير بشكل جيد. مع ظهور التعلم الآلي، أصبحت الأنظمة تعتمد على النماذج الإحصائية المستندة إلى بيانات التدريب.
حالياً، تهيمن نماذج التعلم العميق على مجال معالجة اللغة الطبيعية، وخاصة نماذج based on Transformer architecture. هذه النماذج قادرة على تعلم تمثيلات عميقة للغة من كميات هائلة من البيانات النصية، مما يمكنها من تحقيق أداء مذهل في مهام فهم اللغة وتوليدها.
مثال على تطبيق معالجة اللغة الطبيعية: أنظمة المساعدين الافتراضيين مثل Siri وGoogle Assistant التي تفهم أوامر المستخدمين وتستجيب لها بشكل طبيعي. تطبيق آخر هو ترجمة جوجل التي تستخدم نماذج متقدمة لترجمة النصوص بين اللغات مع الحفاظ على المعنى والسياق.
الرؤية الحاسوبية
الرؤية الحاسوبية (Computer Vision) هي مجال من مجالات الذكاء الاصطناعي يهدف إلى تمكين الحواسيب من理解和解释المحتوى المرئي في العالم المحيط. تشمل تطبيقات هذا المجال التعرف على الأشياء، كشف الوجوه، تقسيم الصور، وتحليل الفيديو. تعتمد أنظمة الرؤية الحاسوبية الحديثة بشكل كبير على الشبكات العصبية التلافيفية (CNNs) التي أثبتت كفاءة عالية في معالجة البيانات المرئية.
عملية معالجة الصور في أنظمة الرؤية الحاسوبية تمر بعدة مراحل. أولاً، تقوم الخوارزميات باستخراج الميزات (Features) من الصور الأولية، مثل الحواف، الزوايا، والأنسجة. ثم يتم combinar هذه الميزات في مستويات أعلى للتعرف على الأنماط والأشكال المعقدة. أخيراً، تستخدم هذه التمثيلات لأداء مهام محددة مثل التصنيف أو الكشف.
من التطبيقات العملية للرؤية الحاسوبية: السيارات ذاتية القيادة التي تستخدم أنظمة رؤية حاسوبية للكشف عن المشاة، الإشارات المرورية، والعوائق الأخرى على الطريق. تطبيق آخر هو التشخيص الطبي المساعد، حيث تساعد الأنظمة الأطباء في تحليل الصور الطبية مثل الأشعة السينية والتصوير بالرنين المغناطيسي.
النماذج التوليدية
النماذج التوليدية (Generative Models) هي فئة من نماذج الذكاء الاصطناعي التي تتعلم distribution البيانات التدريبية لتتمكن من إنشاء عينات جديدة تشبه البيانات الأصلية. على عكس النماذج التمييزية (Discriminative Models) التي تتعلم التمييز بين الفئات، تركز النماذج التوليدية على فهم structure البيانات لتوليد محتوى جديد.
هناك عدة أنواع من النماذج التوليدية، including Generative Adversarial Networks (GANs) وVariational Autoencoders (VAEs) والنماذج التوليدية based on المحولات (Transformers). كل نوع له مزايا وتطبيقات مختلفة. على سبيل المثال، تُستخدم GANs غالباً لتوليد صور واقعية، بينما تُستخدم النماذج based on المحولات لتوليد النصوص.
تعمل شبكات GANs من خلال مواجهة between شبكتين: المولد (Generator) والمميز (Discriminator). يحاول المولد إنشاء عينات واقعية، بينما يحاول المميز التمييز بين العينات الحقيقية والمزيفة. through هذه العملية التنافسية، يتحسن أداء كلا الشبكتين، leading إلى مولد قادر على إنتاج عينات عالية الجودة.
تطبيقات النماذج التوليدية تشمل إنشاء المحتوى الفني، تصميم الأدوية، increase البيانات التدريبية (Data Augmentation)، والمحاكاة. مثلاً، يمكن استخدام هذه النماذج لتوليد وجوه بشرية غير حقيقية but realistic للاستخدام في تصميم الواجهات أو الوسائط الإعلامية.
نموذج المحولات (Transformer)
يعتبر نموذج المحولات (Transformer) أحد أهم التطورات في مجال الذكاء الاصطناعي في السنوات الأخيرة. قدم هذا النموذج في ورقة بحثية بعنوان "Attention Is All You Need" في عام 2017، وأحدث ثورة في مجالي معالجة اللغة الطبيعية والرؤية الحاسوبية. الميزة الرئيسية لهذا النموذج هي آلية الاهتمام (Attention Mechanism) التي تسمح للنموذج بوزن أهمية different أجزاء من بيانات الإدخال.
يتكون نموذج المحولات من encoder وdecoder، كل منهما يتألف من طبقات متعددة. في كل طبقة، هناك آليات اهتمام ذاتية (Self-Attention) وطبقات feed-forward. آلية الاهتمام الذاتي تمكن النموذج من النظر إلى كامل sequence الإدخال simultaneously ووزن أهمية كل部分 بالنسبة للآخرين، مما يحسن فهم السياق.
ميزة أخرى مهمة لنموذج المحولات هي قابليته للتوسع (Scalability)، حيث يمكن تدريبه على كميات هائلة من البيانات مع عدد كبير من المعلمات. هذه القابلية للتوسع أدت إلى ظهور نماذج اللغة كبيرة الحجم (Large Language Models) مثل GPT系列 وBERT التي حققت أداءً متميزاً في مجموعة wide من المهام.
مثال على كيفية عمل آلية الاهتمام: عند ترجمة جملة من الإنجليزية إلى العربية، يمكن للنموذج أن "يهتم" بكلمة في اللغة الإنجليزية عند generating الكلمة المقابلة في العربية، حتى إذا كانت الكلمتين غير متجاورتين في الجملة. هذه القدرة على modeling التبعيات طويلة المدى هي ما يجعل المحولات فعالة جداً في مهام معالجة اللغة.
عملية تدريب النماذج
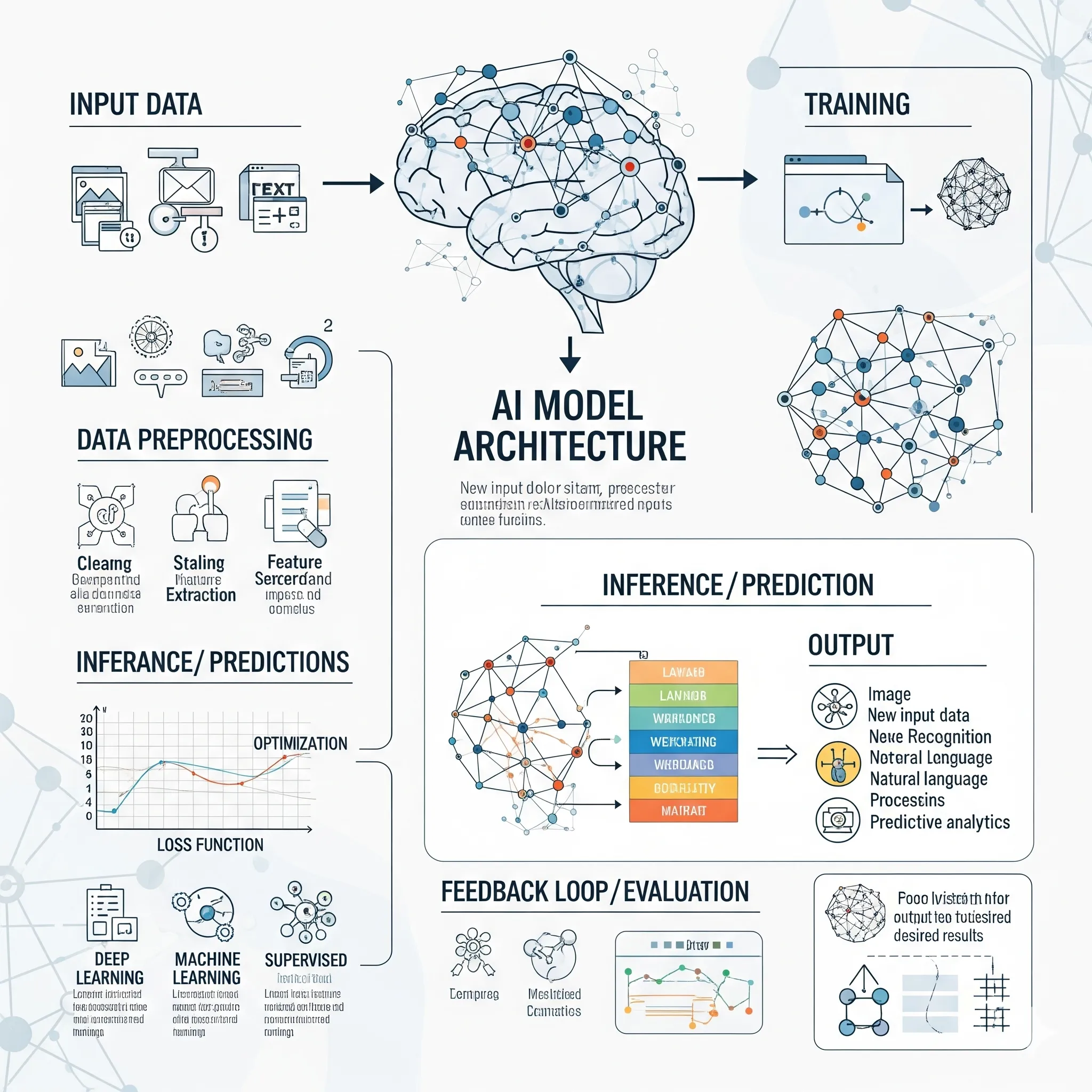
عملية تدريب نماذج الذكاء الاصطناعي هي عملية تكرارية تهدف إلى optimize معلمات النموذج لتقليل خطأ التوقع. تبدأ هذه العملية بتهيئة المعلمات بشكل عشوائي، then تتكرر دورات من التمرير الأمامي (Forward Pass) والتمرير الخلفي (Backward Pass) حتى converges النموذج.
في التمرير الأمامي، تمر بيانات التدريب through النموذج لتوليد predictions. ثم يتم حساب دالة الخسارة (Loss Function) التي تقيس الفرق between التوقعات والقيم الحقيقية. الهدف هو minimize هذه الدالة. في التمرير الخلفي، يتم حساب gradient دالة الخسارة بالنسبة to كل معلمة باستخدام خوارزمية backpropagation، ثم يتم update المعلمات في الاتجاه المعاكس للgradient باستخدام optimization algorithm مثل Adam أو SGD.
من التحديات الرئيسية في تدريب النماذج الكبيرة: ظاهرة overfitting، حيث يتعلم النموذج patterns خاصة ببيانات التدريب بدلاً من general patterns. لمكافحة هذه الظاهرة، يتم استخدام تقنيات regularisation مثل Dropout وWeight Decay، وكذلك تقسيم البيانات إلى مجموعات تدريب واختبار وتحقيق (Validation).
مع زيادة حجم النماذج وكمية البيانات، أصبح تدريب النماذج يتطلب موارد حاسوبية هائلة. أدى هذا إلى تطوير تقنيات تدريب متقدمة مثل التدريب المتوزع (Distributed Training) والتدريب المختلط (Mixed Precision Training) لتسريع عملية التدريب وتقليل متطلبات الذاكرة.
تقييم نماذج الذكاء الاصطناعي
تقييم أداء نماذج الذكاء الاصطناعي هو خطوة crucial في عملية التطوير، حيث يسمح بقياس فعالية النموذج وتحديد areas needing improvement. تختلف مقاييس التقييم according لنوع المهمة ونموذج الذكاء الاصطناعي.
في مهام التصنيف، تشمل المقاييس الشائعة: الدقة (Accuracy)، precision، الاستدعاء (Recall)، وF1-score. الدقة تقيس نسبة التوقعات الصحيحة بشكل عام، بينما precision تقيس نسبة التوقعات الإيجابية الصحيحة بين جميع التوقعات الإيجابية. الاستدعاء يقيس نسبة الحالات الإيجابية الفعلية التي تم التعرف عليها correctly. F1-score هو متوسط توافقي between precision والاستدعاء.
في مهام الانحدار، تشمل المقاييس الشائعة: متوسط الخطأ المربع (Mean Squared Error)، متوسط الخطأ المطلق (Mean Absolute Error)، وR-squared. هذه المقاييس تقيس الفرق between القيم المتوقعة والقيم الفعلية، مع اختلاف في كيفية معاقبة الأخطاء الكبيرة.
بالنسبة للنماذج التوليدية، يكون التقييم أكثر تحدياً due لعدم وجود إجابات "صحيحة" محددة. تشمل المقاييس المستخدمة: Inception Score (IS)، Fréchet Inception Distance (FID) للصور، وPerplexity للنصوص. بالإضافة إلى المقاييس الكمية، often يتم إجراء تقييم qualitatif من قبل humans للحكم على جودة المحتوى generated.
التحديات الأخلاقية في الذكاء الاصطناعي
مع تقدم تقنيات الذكاء الاصطناعي وانتشار تطبيقاتها، برزت مجموعة من التحديات الأخلاقية التي under需要 معالجة. These include التحيز (Bias)، الخصوصية، الشفافية، المساءلة، والتأثير على سوق العمل. تتطلب these التحديات تعاوناً between المطورين، policymakers، والمجتمع للتوصل إلى حلول متوازنة.
تحيز الخوارزميات يحدث when تنتج النماذج results تمييزية against فئات معينة من الناس. هذا التحيز often ينبع من تحيز في بيانات التدريب أو design النموذج. لمكافحة هذه المشكلة، يتم تطوير تقنيات like تقليل التحيز (Bias Mitigation) والتدقيق (Auditing) للكشف عن التحيز ومعالجته.
خصوصية البيانات تشكل تحدياً آخر، especially مع النماذج التي تتطلب كميات كبيرة من البيانات للتدريب. هناك قلق من إمكانية استخدام البيانات الشخصية without موافقة أو تسرب معلومات حساسة. تقنيات like التعلم الاتحادي (Federated Learning) والتما差别ية الخصوصية (Differential Privacy) تهدف إلى حماية الخصوصية while تسمح بالاستفادة من البيانات.
الشفافية والمساءلة تتعلقان بفهم how تتخذ النماذج القرارات ومن المسؤول عن هذه القرارات. especially في التطبيقات الحساسة مثل الرعاية الصحية والعدالة، من المهم أن تكون قرارات الذكاء الاصطناعي قابلة للتفسير (Explainable) وخاضعة للمساءلة. هذا أدى إلى emergence مجال الذكاء الاصطناعي القابل للتفسير (Explainable AI - XAI).
اتجاهات مستقبلية في الذكاء الاصطناعي
يتجه مجال الذكاء الاصطناعي towards تطورات مثيرة في المستقبل القريب والبعيد. من المتوقع أن نشهد استمرار scaling النماذج من حيث الحجم والأداء، مع تحسين في كفاءة التدريب والاستدلال. بالإضافة إلى ذلك، هناك اتجاه نحو النماذج متعددة الوسائط (Multimodal Models) التي يمكنها process和理解多种أنواع البيانات مثل النصوص، الصور، والأصوات في نموذج موحد.
أحد المجالات الواعدة هو الذكاء الاصطناعي السببي (Causal AI)، الذي يهدف إلى فهم العلاقات السببية beyond الارتباطات الإحصائية. هذا يمكن النماذج من making توقعات أكثر robust وقابلة للتgeneralization، especially في scenarios مختلفة عن بيانات التدريب.
اتجاه آخر مهم هو الذكاء الاصطناعي الفعال (Efficient AI)، الذي يركز على تطوير نماذج أصغر حجماً وأقل استهلاكاً للطاقة without التضحية بالأداء. هذا مهم لتوسيع نطاق تطبيقات الذكاء الاصطناعي على الأجهزة ذات الموارد المحدودة مثل الهواتف الذكية والأجهزة الطرفية (Edge Devices).
على المدى الطويل، يستمر البحث towards الذكاء الاصطناعي العام (AGI) - أنظمة ذكاء اصطناعي with القدرة على فهم، learn، وتطبيق المعرفة عبر مجموعة wide من المهام على مستوى البشر أو above. بينما يبقى هذا الهدف بعيد المنال currently، فإن التقدم المستمر في المجال يقربنا خطوة أخرى من تحقيق هذا الحلم.