مقدمة عامة
هذا المرجع يهدف إلى تقديم شرح شامل ومبسّط لكنه دقيق حول الترميزات (Encodings) وطرق المقارنة والترتيب (Collations) في قواعد البيانات والأنظمة عموماً. سنتناول المفاهيم الأساسية، أمثلة عملية، تعليمات لتطبيق أفضل الممارسات في قواعد بيانات مشهورة مثل MySQL وPostgreSQL، ونشرح أيضاً القضايا المتقدمة مثل التطبيع (Normalization)، مشاكل الإيموجي، وتأثير الاختيارات على الأداء والبحث والفرز.
ما هو الترميز (Encoding)؟
الترميز هو الطريقة التي تمثل بها الحروف والرموز نصاً على شكل أرقام (بايتات). الحاسوب لا يتعامل مع الحروف كنصوص بل كقِيَم رقمية. كل ترميز يعرّف خريطة بين الحروف والرقم أو مجموعة البايتات التي تمثلها. عند كتابة كلمة باللغة العربية مثل "مرحبا" يتم تشفيرها إلى بايتات بحسب الترميز المستخدم، وعند القراءة يقوم النظام بفك تشفير البايتات إلى حروف مفهومة.
من دون توافق على الترميز بين مكوّنات النظام (قاعدة بيانات، خادم تطبيقات، واجهة مستخدم، API) ستظهر أخطاء وتمثيلات خاطئة على شكل علامات استفهام أو مربعات أو رموز غير مفهومة.
لماذا يوجد تعدد في الترميزات؟
- التاريخ: ظلت الأنظمة القديمة تستخدم ترميزات محلية أو مخصّصة قبل ظهور معايير شاملة.
- اللغات: بعض الترميزات متخصصة لمجموعات لغوية معينة (مثلاً: ISO-8859-6 للعربية).
- الكفاءة: بعض الترميزات أكثر اقتصادية من ناحية الحجم لبيئات معينة (مثل ASCII للإنجليزية).
- التوافق العكسي: تطبيقات قديمة تتطلب استخدام ترميزات قديمة لتعمل دون تعديل.
أنواع الترميزات الشائعة
ASCII
نظام قديم جداً يستخدم 7 بت ويمثل 128 رمزاً فقط (الإنجليزية والأرقام وبعض الرموز). لا يناسب لغات غير الإنجليزية.
ISO-8859 family
سلسلة ترميزات كل واحدة تدعم مجموعة لغات من منطقة معينة. مثال: ISO-8859-1 لغات أوروبا الغربية، ISO-8859-6 للعربية. ميزة: بسيطة ومباشرة. عيب: لا تصلح لتطبيقات متعددة اللغات.
Windows-125x
نسخ طورتها مايكروسوفت وتحلّ محلّ بعض ترميزات ISO في بيئات ويندوز. لكل لغة أو مجموعة لغات إصدار خاص مثل Windows-1256 للعربية.
Unicode / UTF (مثل UTF-8, UTF-16, UTF-32)
معيار Unicode يهدف لتمثيل كل الحروف في العالم في جدول موحّد. توجد طرق ترميز متعددة ضمن Unicode:
- UTF-8: الأكثر شيوعاً على الويب. ترميز متغير الطول: الحروف الإنجليزية 1 بايت، العربية عادة 2 أو 3 بايت، وبعض الرموز 4 بايت. داعم لجميع اللغات وإيموجي.
- UTF-16: وحدة قياس أساسية 2 بايت لكن بعض الأحرف تحتاج 4 بايت. مستخدم داخل بعض الأنظمة واللغات (مثل Java داخلياً).
- UTF-32: كل حرف يأخذ 4 بايت ثابتة. سهل للمعالجة لكن مساحته كبيرة.
معيار Unicode وUTF — نقاط مهمة
Unicode ليس ترميزاً بل هو معيار يعرّف مجموعات الحروف وأرقامها (Code Points). الترميزات مثل UTF-8 هي طرق لتمثيل هذه الرموز على شكل بايتات. الاعتماد على Unicode وUTF-8 يعني أنك تستطيع تخزين لغات متعددة في نفس العمود دون مشاكل أساسية.
في قواعد بيانات حديثة يشيع استخدام utf8mb4 في MySQL لأن النسخة الأقدم utf8 في MySQL كانت لا تدعم كامل نقاط Unicode (لم تدعم الإيموجي وبعض الرموز التي تتطلب 4 بايت). لذا ظهر utf8mb4 ليدعم 4 بايت كاملة.
ما هو Collation ولماذا نحتاجه؟
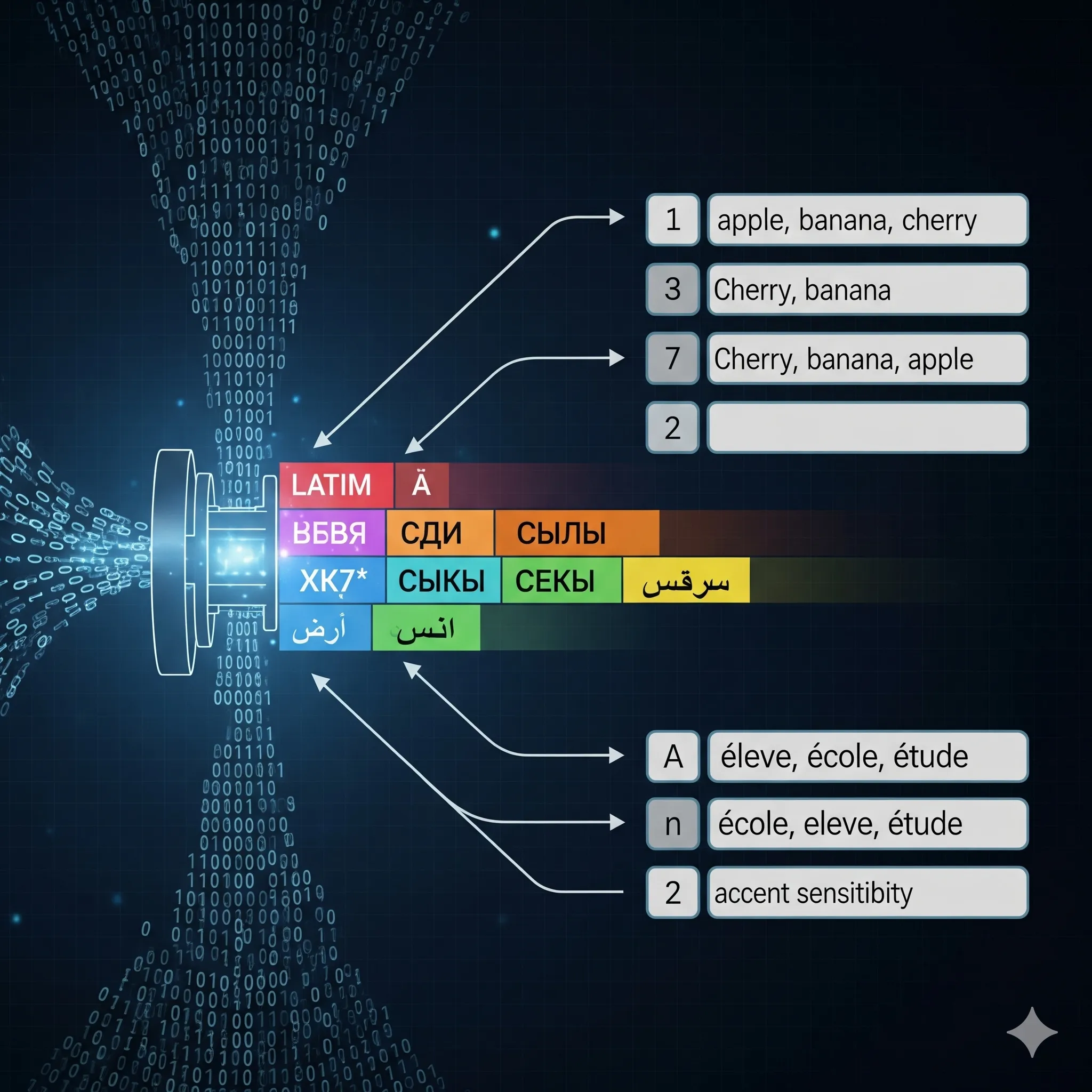
الـ Collation يحدد قواعد المقارنة والترتيب بين النصوص. هو المسئول عن: هل تُعتبر الحروف الكبيرة والصغيرة متماثلة؟ هل تُعامل الحروف ذات العلامات (accents) كحروف منفصلة أم مساوية؟ ويؤثر على نتائج عمليات WHERE وORDER BY وGROUP BY.
كل مجموعة أحرف (Character Set) لها احتمالات متعددة من Collations. في MySQL مثلاً يمكنك أن ترى العديد من الـ Collations لــ utf8mb4.
شرح utf8mb4_unicode_ci بالتفصيل
الاسم مقسوم لثلاثة أجزاء:
- utf8mb4: مجموعة الأحرف (Character Set) — نسخة من UTF-8 تدعم إلى 4 بايت لكل رمز.
- unicode: طريقة المقارنة تعتمد على قواعد معيار Unicode (أي أنها تحاول تطبيق القواعد الرسمية للمقارنة والترتيب وفق Unicode).
- ci: اختصار لـ case-insensitive — أي لا تفرق بين الحروف الكبيرة والصغيرة أثناء المقارنة.
بالتالي هذا الـ Collation يعني: استخدام ترميز يدعم كل العالم، والمقارنات تتم بحسب قواعد Unicode، وغير حساس لحالة الحروف.
سلوك المقارنة والبحث
مثال عملي: في هذا الـ Collation تكون الكلمات التالية متساوية عند المقارنة أو في شرط WHERE: "Resume" و"résumé" و"RESUME" — ذلك لأن المقارنة تتجاهل الاختلاف في حالة الحروف وقد تعدل بعض الفروق البسيطة في العلامات حسب قواعد Unicode.
متى نستخدمه؟
عندما نحتاج دقة مقارنة عالية ومتوافقة مع Unicode وفي نفس الوقت نريد تجاهل فرق الحالة (الكبيرة/الصغيرة). مناسب للمواقع متعددة اللغات حيث نريد نتائج بحث وترتيب متوقعة للمستخدمين.
مقارنة عملية: utf8mb4_general_ci vs utf8mb4_unicode_ci vs utf8mb4_bin
utf8mb4_general_ci
سريع نسبياً، لكنه تبسيطي في قواعد المقارنة ولا يتبع كل تفاصيل Unicode. قد يعطي نتائج مختلفة في الحالات اللغوية الحساسة.
utf8mb4_unicode_ci
أدق من general لأنه يتبع قواعد Unicode، لكنه أبطأ قليلاً في الحركات المقارنة والفرز.
utf8mb4_bin
يفعل مقارنة ثنائية (binary) على مستوى البايتات، أي يكون حساساً للحالة ولتفاصيل البايت. يستخدم عندما تحتاج مقارنة صارمة (مثلاً في كلمات المرور أو مفاتيح فريدة يجب أن تكون حساسة للحالة).
مقارنة ملخّصة
- الحساسية للحالة:
utf8mb4_bin(حساس) vs_ci(غير حساس) - الدقة اللغوية:
unicode_ciأعلى منgeneral_ci - الأداء:
general_ciأسرع منunicode_ciفي بعض الحالات؛ الفرق غالباً ضئيل وحدودياً ملحوظة في قواعد بيانات كبيرة جداً.
تاريخ تطور الترميزات — من البداية إلى الآن
في البداية، ومع أنظمة الحاسوب الأولى، كانت الحاجة لتمثيل النص محدودة بالإنجليزية. ظهر ASCII في سبعينات القرن الماضي لتمثيل الحروف الإنجليزية. لاحقاً نما الاهتمام بدعم لغات أخرى فظهرت ترميزات إقليمية مثل ISO-8859 وسلاسل Windows-125x. كل بيئة اختارت ترميزاً مناسباً لمنطقتها، فتبنت أنظمة عديدة.
ومع توسع الإنترنت وظهور الحاجة لمواقع متعددة اللغات، أصبحت المشاكل المتعلقة بالتوافق بين الترميزات ظاهرة ومؤلمة — نصوص تصبح غير مفهومة عند نقلها بين أنظمة مختلفة. استجابة لذلك طُوِّر معيار Unicode الذي هدف لتوحيد تمثيل الحروف في جدول واحد. بعد ذلك ظهرت طرق ترميز مثل UTF-8 وUTF-16. ومع الوقت أصبح UTF-8 الاختيار الشائع بسبب مرونته وكفاءته في التعامل مع نصوص إنجليزية وكونه مضغوطاً للغات الغربية بينما يظل قادراً على تمثيل لغات أخرى.
قواعد البيانات تبنت هذه التوجهات تدريجياً؛ في MySQL مثلاً ظهرت مشكلة أن ترميز utf8 القديم لم يكن كاملاً (لم يكن يدعم نقاط Unicode التي تتطلب 4 بايت) فاستُحدث utf8mb4 كبديل كامل يدعم الإيموجي وكل الرموز الحديثة.
أمثلة عملية في MySQL
إنشاء قاعدة بيانات مع utf8mb4 وutf8mb4_unicode_ci
CREATE DATABASE mydb
CHARACTER SET = utf8mb4
COLLATE = utf8mb4_unicode_ci;
إنشاء جدول وعمود نصي محدد له الترميز والـ Collation:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci
);
تغيير ترميز وجدول إلى utf8mb4
ALTER TABLE mytable CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;ملاحظة: قبل تشغيل الأمر أعلاه من الأفضل أخذ نسخة احتياطية لأن التحويل قد يتسبب ببيانات تالفة إذا كانت البيانات الأصلية مخزنة بترميز غير مطابق فعلياً.
التأكد من إعداد الاتصال (مثال في PHP)
$pdo = new PDO('mysql:host=localhost;dbname=mydb;charset=utf8mb4', $user, $pass, [
PDO::MYSQL_ATTR_INIT_COMMAND => 'SET NAMES utf8mb4'
]);
من المهم التأكد أن اتصال التطبيق بقاعدة البيانات يحدد نفس الترميز لتجنّب مشكلات التشفير أثناء النقل.
خطوات وآليات تحويل قواعد البيانات لغاية الترميز الموحد
عند ترقية قاعدة بيانات قديمة لاستخدام utf8mb4 وCollation حديث، اتبع هذه الخطوات العامة:
- خذ نسخة احتياطية كاملة (dump) من قاعدة البيانات.
- افحص الترميزات الحالية للأعمدة والجداول باستخدام أوامر مثل
SHOW CREATE TABLEأو فحص مخطط البيانات. - حول تدريجياً الجداول:
ALTER TABLE ... CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; - تأكد من ضبط إعدادات الاتصال للتطبيق (SET NAMES utf8mb4 أو استخدام PDO/Connector مع charset parameter).
- اختبر كمية البيانات النصية خصوصاً الحقول التي تحتوي رموزاً خاصة أو إيموجي.
- راجع مؤشرات وترتيب وفرز النصوص بعد التحويل للتأكد من النتائج.
في بعض الحالات قد تحتاج إلى تحويل البيانات يدوياً عندما تكون مخزنة بشكل خاطئ مسبقاً (مثلاً تم تفسیر بايتات UTF-8 كـ Latin1). هناك تقنيات لإصلاح ذلك تتضمن فك الترميز ثم إعادة تشفيره بالترتيب الصحيح.
Normalization وNFC/NFD ولماذا تهم
Unicode يمكن أن يمثل نفس الرمز بعدة طرق. على سبيل المثال الحرف "é" يمكن أن يمثل كرمز واحد (U+00E9) أو كرمز "e" متبوع بعلامة نغمة (combining accent). هاتان الطريقتان متساويتان بصرياً لكنهما مختلفتان على مستوى الكود. لذلك ظهر مفهوم التطبيع (Normalization) لتحويل النص إلى شكل موحّد قبل المقارنة أو التخزين أو الحساب على السلاسل.
الشكلان الشائعان هما:
- NFC (Normalization Form C): يحاول دمج الرموز وإنشاء تمثيل مركب عندما يكون ذلك ممكناً.
- NFD (Normalization Form D): يفكك الرموز إلى قاعدة + علامات تجميع (combining marks).
من الأفضل في التطبيقات الحساسة أن تحدد وتطبق شكل تطبيع موحّد (مثلاً NFC) قبل تخزين أو مقارنة النصوص.
الإيموجي والرموز الحديثة — مشاكل وحلول
الإيموجي غالباً ما يحتاج إلى نقاط Unicode خارج نطاق 3 بايت، لذلك استخدام utf8mb4 في MySQL ضروري لدعمها. إذا بقيت على utf8 القديم (المقصود به في MySQL الذي لا يدعم 4 بايت)، فستظهر الرموز على شكل علامات استفهام أو سيحدث error عند الإدراج.
تأكد من أن كل مستويات النظام (قاعدة البيانات، جدول، عمود، اتصال التطبيق) تدعم utf8mb4. كذلك قم باختبار إدراج واسترجاع إيموجي للتأكد.
المؤشرات (Indexes) وتأثير الـ Collation عليها
عند إنشاء فهرس على عمود نصي فإن ترتيب وترميز ذلك الفهرس يتأثر بالـ Collation. بعض الـ Collations تتطلب حجم مفتاح أكبر بسبب طريقة التمثيل ولذلك قد تواجه قيوداً على طول الفهرس (index length). في MySQL مع utf8mb4 الافتراضي، بايتات الحرف قد تصل إلى 4 بايت وهو ما يعني أن طول الحقل المقبول للفهرس قد يكون أقل عملياً مقارنة بـ ASCII.
نقطة عملية: إذا أردت أن يكون لديك فهرس على عمود VARCHAR(255) باستخدام utf8mb4 قد تحتاج لتقليل الطول أو استخدام فهرس جزئي (prefix index) أو ضبط إعدادات المحرك (مثل تغيير innodb_large_prefix في الإصدارات القديمة).
الأداء، التخزين، وحجم البيانات
الاختيار بين UTF-8 وUTF-16 يؤثر على حجم البيانات. UTF-8 فعّال للغات التي تستخدم حروفاً لاتينية (1 بايت لكل حرف غالباً) بينما قد يزيد حجم النص للغات الآسيوية. UTF-16 قد يكون أكثر كفاءة لبعض اللغات الآسيوية لكنه أكبر للحروف اللاتينية. يجب أن تختار بناءً على طبيعة البيانات في تطبيقك.
الـ Collation قد يؤثر على سرعة عمليات البحث والترتيب. الـ Collations الأكثر دقة (مثل unicode_ci) تتطلب قواعد أكثر تعقيداً وتكون عملياتها أبطأ قليلاً من الـ Collations البسيطة (general_ci) أو الـ binary.
المشاكل الشائعة وحلولها
ظهور رموز غريبة (mojibake)
هذا يحدث عندما تُفسَّر البايتات بترميز مختلف عن الترميز الحقيقي. الحل يكمن في تحديد الترميز الصحيح عند القراءة والكتابة وتصحيح الاتصالات (SET NAMES أو ضبط الConnector).
بيانات مخزنة بترميز خاطئ
في بعض الحالات تكون البيانات مخزنة فعلياً كـ Latin1 بينما تُعتبر UTF-8 — تحتاج لتحويلها عبر خطوات مخصوصة (مثلاً: قراءة النص كـ Latin1 ثم إعادة تشفيره إلى UTF-8 ثم حفظه).
قيود طول الفهارس
انظر قسم المؤشرات — استخدم prefix index أو قلل طول الحقول أو غيّر إعدادات المحرك.
أفضل الممارسات الحديثة
- اعمل على توحيد الترميز في كامل النظام: قاعدة بيانات، جداول، أعمدة، اتصالات، وواجهات.
- استخدم
utf8mb4في MySQL مع Collation مناسب مثلutf8mb4_unicode_ciأوutf8mb4_general_ciحسب الحاجة. - اضبط الاتصال من التطبيق (مثلاً: PDO أو mysqli) ليستخدم
SET NAMES utf8mb4أو تحديد charset في سلسلة الاتصال. - فكّر في Normalization (NFC) قبل التخزين إن كانت تطبيقاتك تحتاج لمقارنات نصية حساسة.
- اختبر إدراج واسترجاع الإيموجي والرموز الخاصة للتأكد من الدعم الكامل.
- عند تحويل قواعد بيانات قديمة: خذ نسخة احتياطية، اختبر على بيئة staging، وتأكد من فحص الحقول الحساسة يدويًا.
أدوات وفحوص مفيدة
- أوامر MySQL:
SHOW VARIABLES LIKE 'char%'; SHOW CREATE TABLE ...; - محرّرات نص تدعم اختيار الترميز (مثل برامج تحرير متقدمة أو IDEs).
- أدوات تحويل النصوص والبرمجيات المكتبية التي تسمح باختيار الترميز وإجراء اختبارات.
- اختبارات يدوية: جرب إدخال نصوص متعددة اللغات، رموز مركبة، وإيموجي ثم استخرجها.
الخلاصة والملخص العملي
الترميزات والـ Collations هي جزء حاسم من تصميم قواعد البيانات والتطبيقات. في الغالب اليوم يكون الخيار الأفضل هو توحيد النظام على Unicode باستخدام UTF-8 (في MySQL استخدم utf8mb4) مع Collation مناسب حسب حاجتك (utf8mb4_unicode_ci للدقة اللغوية، أو utf8mb4_general_ci لأداء أسرع قليلاً، أو utf8mb4_bin للمقارنة الثنائية الحساسة).
تذكّر: أهم جزء هو الاتساق — جميع مكوّنات النظام يجب أن تتفق على الترميز والـ Collation لتفادي الأخطاء. اختبر دائماً على نسخة تجريبية قبل تطبيق تغييرات واسعة من أجل حماية جودة البيانات وتجربة المستخدم.
ملاحظات نهائية ومراجع مقترحة للقراءة
راجع توثيق MySQL حول utf8mb4 وCollations، ومواد Unicode Consortium لفهم عميق للقواعد، كما أن مراجع قواعد البيانات الشهيرة (PostgreSQL, SQL Server) تحتوي على معلومات مفيدة حول ممارسات مماثلة. يُنصح بالبحث عن مقالات حول "Unicode normalization" و"Character encoding best practices" لمزيد من التفاصيل التقنية.