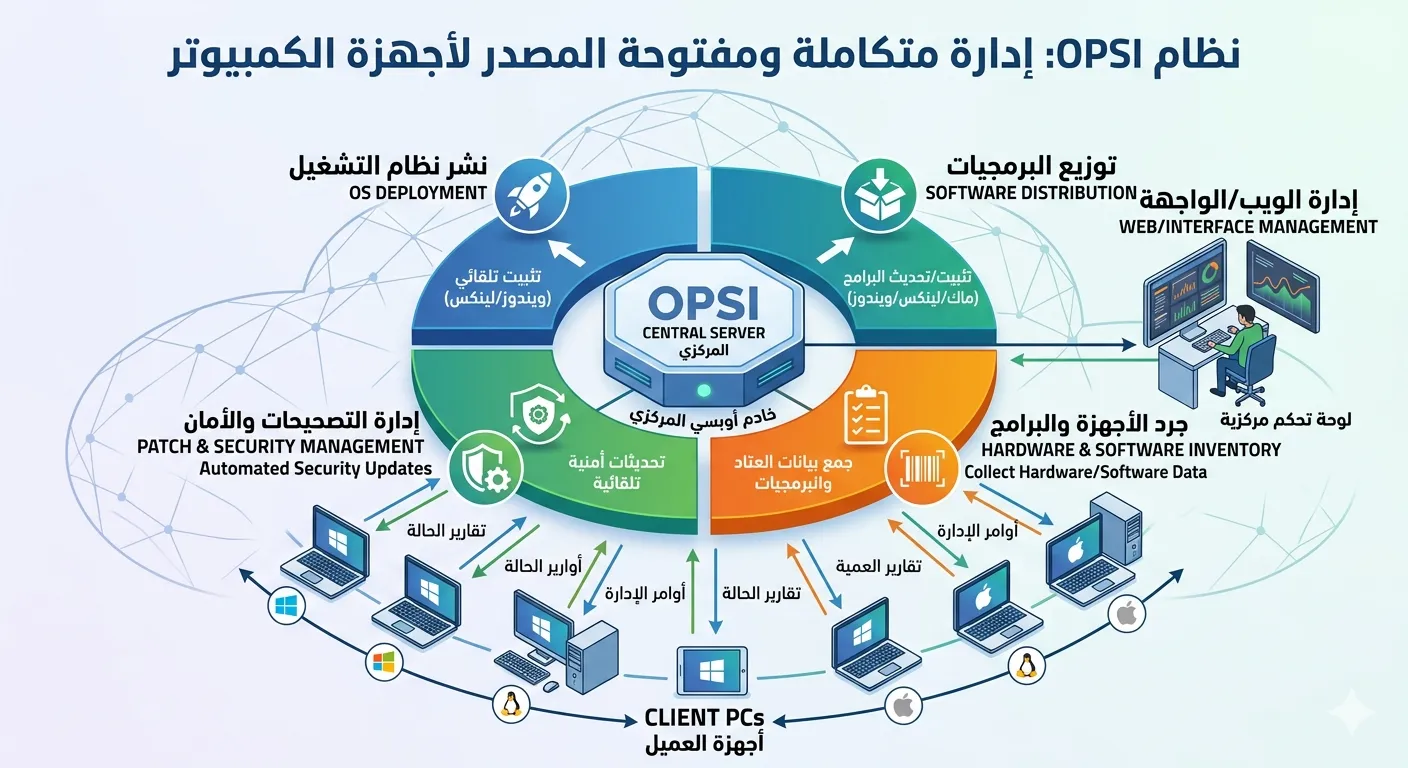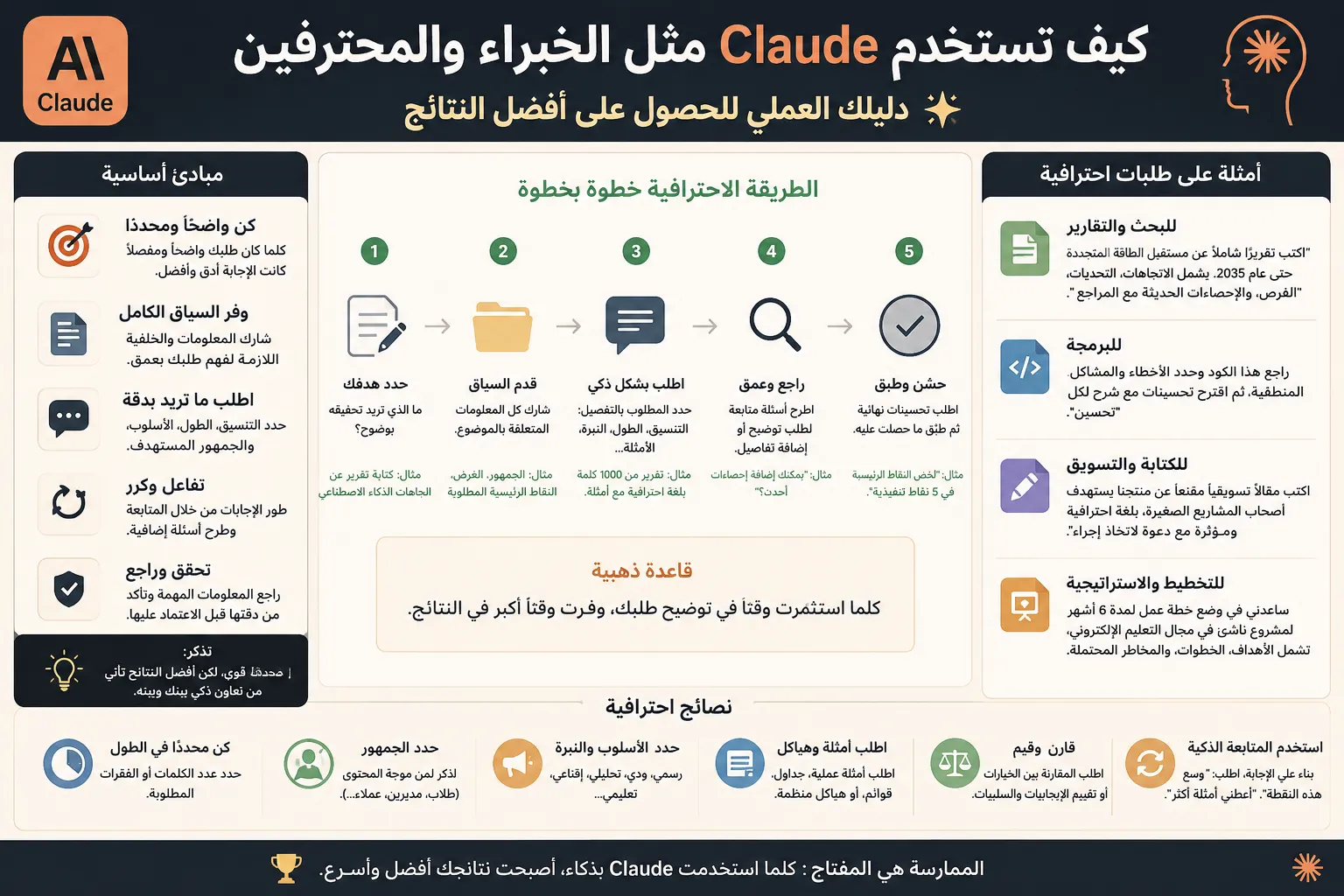
مقدمة موجزة
الذكاء الاصطناعي مجال تقني وعلمي يهدف لبناء أنظمة تستطيع محاكاة بعض جوانب الذكاء البشري أو التفوق عليها في مهام محددة. خلال العقود الماضية، شهد المجال تسارعا كبيرا في القدرات العملية بفضل ازدياد قوة الحوسبة، توفر قواعد بيانات ضخمة، وتطور الخوارزميات. هذا المرجع يقدّم وصفًا متكاملاً لآليات التعلم، نسب التطور المتوقعة، والاستعمالات العملية حتى عام 2030، مع أمثلة وشروحات تقنية مبسطة عند الحاجة.
بدايات وتطور الذكاء الاصطناعي — التاريخ والمراحل
يمكن تقسيم تطور الذكاء الاصطناعي إلى مراحل زمنية متمايزة: مرحلة المفاهيم النظريّة، مرحلة الأنظمة الخبريّة، مرحلة الشبكات العصبية التقليدية، مرحلة تعلم الآلة العميق، والمرحلة الحديثة التي تميّزت بنماذج اللغة الضخمة وتقنيات التعلم الذاتي.
المرحلة النظرية والبدايات
في بدايات القرن العشرين، ظهرت أفكار نظرية حول إمكانية محاكاة الفكر الآلي. تطورت هذه الأفكار إلى محاولات عملية أولية لبناء أنظمة تعمل وفق قواعد منطقية ثابتة، وظهرت أدوات برمجية بدائية وبرامج شطرنج تجريبية. هذه المرحلة كانت أقل اعتمادًا على البيانات وأكثر اعتمادًا على قواعد مبرمجة يدويًا.
الأنظمة الخبيرة والمنطق الرمزي
لاحقًا ظهرت الأنظمة الخبيرة التي تعتمد على قواعد معرفة صريحة وعمليات استدلال منطقية. هذه الأنظمة نجحت في مجالات متخصصة لكن واجهت صعوبة في التعميم والتعامل مع بيانات ضوضائية وغير مكتملة.
ثورة الشبكات العصبية وتعلّم الآلة
مع تقدم الحوسبة وظهور خوارزميات التعلم مثل خوارزميات الانحدار، أشجار القرار، وآليات التجميع، بدأ المجال ينتقل نحو حلول قادرة على تعلم العلاقات من البيانات. دخلت الشبكات العصبية دفعة جديدة خاصة بعد تطوير أساليب التدريب العميق التي حسّنت الأداء في الرؤية الحاسوبية ومعالجة اللغة.
نماذج السفراء: التعلم العميق ونماذج اللغة الضخمة
السنوات الأخيرة شهدت بروز نماذج كبيرة جدًا قادرة على التعامل مع اللغة والصور والصوت بمرونة عالية. نماذج تُدرب على مجموعات بيانات واسعة وتستخدم معماريات متطوّرة قادرة على التعميم والقيام بمهام متعددة دون تدريب مخصص لكل مهمة.
كيف يتعلم الذكاء الاصطناعي؟ أساليب التعلم الأساسية
ثلاثة أنماط رئيسية تُستخدم في معظم تطبيقات الذكاء الاصطناعي:
التعلم المكلَّف (Supervised Learning)
في هذا النمط، يتم تدريب النموذج على أمثلة مدخلة مع ملصقات صحيحة. الهدف أن يتعلم النموذج الاقتران بين المدخلات والتسميات. أمثلة: تصنيف الصور، التنبؤ بالأسعار. يعتمد الأداء على جودة الكمّية والنوعية للبيانات المعلّمة.
التعلم غير المكلَّف (Unsupervised Learning)
يستخدم هذا النمط لاكتشاف بنى أو مجموعات في البيانات دون تسميات. أمثلة: تجميع العناصر (clustering)، خفض الأبعاد (dimensionality reduction). يُستخدم لتحليل البيانات الاستكشافي وإنشاء تمثيلات مضغوطة للبيانات.
التعلم بالتعزيز (Reinforcement Learning)
يتعلم العامل (Agent) من خلال التفاعل مع بيئة والحصول على مكافآت أو عقوبات. هذا النمط مناسب للمشكلات التي تتطلب اتخاذ قرارات متسلسلة مثل التحكم في الروبوتات أو الألعاب المعقدة أو تحسين سياسات تشغيلية في أنظمة تلقائية.
التعلّم الذاتي وتمثيلات ما قبل التدريب (Self-supervised / Pretraining)
طريقة حديثة تعتمد على إنشاء أهداف تدريبية داخلية من نفس البيانات، مثل التنبؤ بجزء مفقود من النص أو الصورة. تقنيات ما قبل التدريب تُنتج نماذج يمكن ضبطها لاحقًا لمهام محددة باستخدام بيانات أقل، مما يخفض تكلفة جمع البيانات المعلّمة ويحسّن التعميم.
التعلم الاتحادي (Federated Learning)
نمط يسمح بتدريب نماذج عبر بيانات موزعة على أجهزة متعددة دون تجميع البيانات في مكان مركزي، مما يحسّن الخصوصية ويقلل حركة البيانات.
معماريات ونماذج بارزة (مفاهيم تقنية)
المعمارية أو التصميم الداخلي للنموذج لها أثر كبير على قدرته. نذكر أهم الأنواع مع شرح مبسّط:
الشبكات العصبية التقليدية (Feedforward Networks)
تتألف من طبقات متتابعة من خلايا حسابية، مفيدة للمشكلات التي لا تتطلب حفظ حالة زمنية طويلة.
الشبكات التلافيفية (Convolutional Neural Networks)
مصممة لمعالجة الصور والمصفوفات ثنائية وثلاثية الأبعاد، تعتمد مرشحات تلتقط السمات المحلية، وتستخدم على نطاق واسع في الرؤية الحاسوبية.
الشبكات التكرارية وآليات الذاكرة (RNN, LSTM, GRU)
كانت شائعة لمعالجة السلاسل الزمنية والنصوص قبل ظهور المعمارية التالية؛ تمتاز بالقدرة على حفظ معلومات زمنية على مدى قصير إلى متوسط.
معمارية المحول (Transformer)
حولت المشهد بتقديم آلية الانتباه (Attention) التي تسمح للنموذج بالتركيز على أجزاء مختلفة من المدخلات بالتوازي، ما يزيد كفاءة التدريب ويعطي نتائج متفوقة في معالجة اللغة، والترجمة، وفهم السياق. المعمارية الأساسية لهذه الفئة أدّت إلى نماذج لغة ضخمة قادرة على أداء مهام متنوعة.
نماذج التوليد (Generative Models)
مثل نماذج التوليد الشرطية، نماذج النماذج التوليدية التنافُسية، ونماذج الانتشار (diffusion models) التي تستخدم بشكل واسع في توليد الصور عالية الجودة، والصوت، والنصوص.
مقاييس التقييم ونسبة التحسن
قياس تطور الذكاء الاصطناعي يعتمد على مؤشرات كمية وكيفية. أهم المقاييس:
- الدقة والموثوقية: مقاييس مثل Accuracy, Precision, Recall, F1 في مسائل التصنيف.
- مقاييس الخسارة: مثل Cross-Entropy وMSE التي تقيس مدى اقتراب التنبؤ من الحقيقة.
- زمن الاستجابة والاستهلاك الحسابي: زمن الاستدلال (Inference latency) وعدد المعاملات الحسابية FLOPs وحجم النموذج (Parameters).
- مقاييس عامة للنماذج اللغوية: مثل perplexity أو مقاييس مهام معيارية خاصة بالترجمة، الفهم، أو الإجابة على الأسئلة.
- مقاييس إنتاجية اقتصادية: قياس الزيادة في الإنتاجية أو التوفير في التكاليف نتيجة استخدام نظم ذكية.
على مستوى نسب التحسّن، شهدت السنوات الأخيرة انخفاضًا كبيرًا في معدل الخطأ على مهام معيارية مثل التعرف على الصور والترجمة الآلية، كما تحسّن الأداء في فهم النصوص الطويلة والسياق. نسبة التحسّن تختلف حسب المجال: في الرؤية الحاسوبية قد تكون التحسينات متدرجة، أما في معالجة اللغة فقد حققت نماذج كبيرة قفزات نوعية.
أفضل الطرق الحديثة في 2024-2025 وما بعدها
تطورت طرق وممارسات صناعة النماذج بسرعة، وفيما يلي أبرزها:
1. التدريب المسبق ثم الضبط الدقيق (Pretraining + Fine-tuning)
تدريب نماذج عامة على مجموعات بيانات ضخمة، ثم ضبطها لمهام مرجعية باستخدام بيانات أصغر يوفّر أداءً ممتازًا ويوفّر موارد التدريب الخاصة بكل مهمة.
2. التعلم الذاتي (Self-supervised Learning)
تقنيات تعتمد على مهام داخلية مستخرجة من نفس البيانات (مثل ملء الكلمات المفقودة) لتكوين تمثيلات قوية دون الحاجة لتسميات بشرية مكلفة.
3. التحويلات الصغيرة والفعّالة (Efficient Transformers)
إصدارات محسّنة من معمارية المحول تقلل استهلاك الذاكرة والوقت، وتسمح بالتطبيق على الأجهزة الطرفية والهواتف.
4. التعلم الاتحادي والخصوصية المحسّنة
نماذج تُدرّب على بيانات موزعة وتستخدم أساليب تشفير أو تضليل لضمان خصوصية بيانات المستخدمين، مع الحفاظ على جودة النموذج.
5. توليد بيانات صناعية (Synthetic Data)
استخدام نماذج توليد لإنشاء بيانات تدريبية تعوّض نقص البيانات الحقيقية، ما يسرّع التجريب ويقلل الاعتماد على جمع بيانات حساسة.
6. AutoML وأتمتة تصميم النماذج
أدوات وأُطر تسهّل اختيار العمارة، معلمات التدريب، واستراتيجية التهيئة تلقائيًا لتقليل الحاجة لخبراء متخصصين لكل حالة.
7. نماذج مُتعددة الوسائط (Multimodal Models)
نماذج تفهم وتولّد بيانات متعددة الوسائط — نص، صوت، صور، وفيديو — مما يفتح آفاقًا جديدة في التفاعل والتطبيقات.
8. الاعتماد على معيارية ومكتبات MLOps
جاهزية النماذج للإنتاج أصبحت تركز على تدفق عمل متكامل يشمل إدارة البيانات، التجارب، المراقبة، والتحديثات الدورية بنمط آمن وموثوق.
تطبيقات عملية في قطاعات مختلفة
الذكاء الاصطناعي يطبّق على نطاق واسع في قطاعات متعددة. نذكر أمثلة وتفصيلًا لكيفية الاستفادة:
الرعاية الصحية
تحسين تشخيص الصور الطبية، دعم اتخاذ القرار العلاجي، اكتشاف الأنماط في بيانات المرضى للتنبؤ بالمخاطر. مثال توضيحي: نظام يقيس احتمالية ظهور مضاعفات بعد عملية جراحية بناءً على سجل رقمي للمرضى، يستخدم ميزات إحصائية وتعلم آلي للتنبؤ بنسبة المخاطر.
التعليم
تخصيص التجربة التعليمية باستخدام أنظمة توصية للمحتوى، تقييم تلقائي للمهمات الكتابية، وتوفير مساعدين تعلم ذكيين يقدمون توجيهًا فرديًا.
النقل واللوجستيات
تحسين الجداول والمسارات، التنبؤ بحركة المرور، إدارة أساطيل ذكية، واستخدام روبوتات مستقلة في المستودعات. مثال: نظام تخطيط مسارات يقلل زمن التسليم بافتراض خرائط حركة ومقاييس زمنية أُخذت من بيانات سابقة.
الخدمات المالية
كشف الاحتيال، تحليل المخاطر الائتمانية، وأتمتة عمليات خدمة العملاء عبر وكلاء ذكاء اصطناعي قادرين على فهم اللغة.
الصناعة والتصنيع
الصيانة التنبؤية، مراقبة الجودة بالصور، وتحسين خط الإنتاج باستخدام تحليلات زمنية متقدمة.
تأثير الذكاء الاصطناعي على الاقتصاد والإنتاجية
الذكاء الاصطناعي قد يزيد من كفاءة العمليات ويخفض التكاليف التشغيلية. النتائج المتوقعة تشمل زيادة في الناتج الإجمالي، تحوّل فرص العمل نحو مهارات تحليلية وتقنية أكثر، وتغيّر في هيكل بعض الصناعات. من المهم تبنّي سياسات تدريب وإعادة تأهيل للقوى العاملة لموازنة تأثير الأتمتة.
الطاقة والاستدامة وحجم الموارد المطلوبة
نماذج التدريب الكبيرة تتطلب طاقة وحوسبة كبيرة. التحدي هو تحقيق توازن بين الفوائد والتكاليف البيئية. التقنيات الحديثة تسعى لتقليل البصمة الكربونية عبر تحسين كفاءة الخوارزميات، استخدام مراكز بيانات تعمل بالطاقة المتجددة، وتصميم نماذج خفيفة تناسب الأجهزة الطرفية.
المخاطر والأخلاقيات والتنظيم
المخاطر تشمل التحيز في النماذج، انتهاكات الخصوصية، الاستخدامات الخبيثة، وفقدان الوظائف في قطاعات معينة. لذا فإن تنظيم الاستخدام، وضع إطار شفاف للمساءلة، وتطوير أنظمة قابلة للتفسير ضروري. يشمل ذلك سياسات للبيانات، تقييم الأثر الأخلاقي، ومؤشرات لجودة النموذج وسلوكه.
كيف سيكون شكل الذكاء الاصطناعي في عام 2030 — سيناريوهات عملية
إليك سيناريوهات عملية متوقعة لمرحلة 2030، مع نسب تقريبية للتبني بحسب المجالات (تقديرات مبنية على اتجاهات حالية وليست قطعًا حتميًا):
سيناريو واقعي متدرج (الأرجح)
توسّع واسع في استخدام أدوات الذكاء الاصطناعي في الأعمال، زيادة في تبنّي نماذج اللغة والنماذج المتعددة الوسائط في الشركات، تطبيقات أتمتة في المهام الروتينية، واستمرار الحاجة لتدخل بشري في القرارات الحساسة. قد تصل نسبة المهام المؤتمتة في قطاعات محددة إلى 20–40% حسب طبيعة العمل.
سيناريو تسارعي (مُسرّع)
تحسّن كبير في نماذج عامة قادرة على أداء مجموعات أوسع من المهام (نماذج أقرب إلى الذكاء العام الضيق)، يؤدي إلى أتمتة أسرع في قطاعات الخدمات والمهن المعرفية. في هذا السيناريو، قد تتغير بعض الوظائف بشكل جذري خلال سنوات قليلة.
سيناريو تحوّطي (تقني أو تنظيمي)
مخاطر بيئية أو تشريعات صارمة قد تحد من انتشار بعض التطبيقات عالية الاستهلاك للطاقة أو تلك التي تنتهك الخصوصية. التركيز ينقل إلى حلول فعالة ومستدامة ومقننة جيدًا.
بشكل عام، بحلول عام 2030 من المتوقع أن تكون الأدوات أكثر قدرة على التفاهم باللغة الطبيعية، أسرع في الاستدلال، وأوفر من حيث التكلفة بالنسبة للمهام الشائعة، مع انتشار أكبر للنماذج على الأجهزة الطرفية والبيئة السحابية معًا.
حالات وأمثلة توضيحية مفصّلة
مثال 1: نظام توصية في متجر إلكتروني
وصف: نظام يقترح منتجات للمستخدمين بناءً على سلوكهم وتاريخ عمليات الشراء. مكوّنات العملية: جمع بيانات السلوك، استخراج ميزات المستخدم والمنتج، بناء نموذج تصنيف أو نظام عامل مشترك (collaborative filtering)، وتقييم الأداء بواسطة مقاييس مثل معدل النقر والتحويل.
مثال 2: نموذج تصنيف صور طبية
وصف: نموذج رؤية حاسوبية يصنّف صورًا طبية (مثل صور الأشعة) إلى فئات معينة. خطوات العمل: تجهيز البيانات، تقسيم إلى تدريب/تقييم، استخدام بنية شبكة تلافيفية، تدريب على مجموعة مُوسعة، ثم ضبط دقيق متبوعا باختبارات سريرية للتحقق من جدارة النموذج قبل الاستخدام العملي.
مثال 3: روبوتات مستودعات ذكية
وصف: منظومة روبوتية تدير تحريك البضائع داخل مستودع، ترتبط بأنظمة تتبع المخزون وتخطّط المسارات. تقنيات مستعملة: الرؤية الحاسوبية، تخطيط المسارات، التحكم التلقائي، وتعلم التعزيز لتحسين سياسات الحركة والتنسيق بين الروبوتات.
توقعات التبني في المنطقة (ملاحظات عامة)
معدلات التبني تعتمد على البنية التحتية، القوى البشرية المتخصصة، وتوافر البيانات. من المتوقع تباطؤ في التبني في مناطق تفتقد لبنية سحابية قوية أو سياسات بيانات واضحة، بينما ستتقدّم القطاعات التي لديها استثمار في التحول الرقمي. السياسات الحكومية، مبادرات التدريب، وتشجيع الشركات الناشئة سيسهمون في تسريع الانتشار الإقليمي.
نصائح للمهتمين: كيف تبدأ وتتبع التطور
- ابدأ بفهم أساسيات الرياضيات والإحصاء وخوارزميات التعلم الآلي الأساسية.
- اطلع على مفاهيم الشبكات العصبية والمعمارية الحديثة مثل المحول.
- جرّب مشاريع عملية بسيطة: تصنيف نصوص أو صور، أو نظام توصية صغير.
- تعلم أدوات إدارة النماذج وإطارات العمل الشائعة ومنهجيات MLOps.
- تابع التطورات البحثية والتقارير الصناعية لتبقى مواكبًا للتقنيات الناشئة.
خاتمة
الذكاء الاصطناعي يتطور بسرعة، ومع كل تقدم تقع فرص جديدة وتظهر تحديات حقيقية. بحلول عام 2030 من المتوقع أن تصبح الأدوات أكثر قوة وتطبيقية، لكن ضمان استخدام مسؤول ومستدام سيظل عاملًا حاسمًا لتحقيق فوائد واسعة وموزعة. التركيز العملي يجب أن يكون على بناء نماذج فعالة، مستدامة، وقابلة للتفسير، مع سياسات توفر حماية للحقوق وتدعم العدالة في الاستخدام.
مراجع ومصادر للاطلاع (مفهرس)
هذه القائمة تشير إلى أنواع مصادر مفيدة للاطلاع ولم تُدرج اقتباسات حرفية ضمن النص. يمكن استخدام محركات البحث العلمي والمواقع المتخصصة لقراءة تقارير عن سوق الذكاء الاصطناعي، أطر العمل التقنية، ومقالات مراجعة حول النماذج المعمارية وتقنيات التدريب.
- تقارير الصناعة حول سوق الذكاء الاصطناعي والنمو الاقتصادي.
- أوراق بحثية تصف معمارية المحول، التعلم الذاتي، ونماذج التوليد.
- مواد تعليمية حول التعلم الآلي، الإحصاء، وMLOps.