مقدمة: ما هو نموذج الذكاء الاصطناعي؟
نموذج الذكاء الاصطناعي هو خوارزمية أو نظام برمجي يتعلم من بيانات ليؤدي مهمة محددة مثل تصنيف محتوى، التنبؤ بقيم مستقبلية، فهم نصوص، أو إنشاء محتوى. التعلم يمكن أن يكون خاضعًا (Supervised)، غير خاضع (Unsupervised)، أو شبه خاضع (Semi-supervised) أو عبر التعلم بالتعزيز (Reinforcement Learning). الهدف من هذا المقال هو تقديم صورة كاملة وواضحة لمن يريد بناء نموذج عملي، مع شرح مفصل للخطوات والأدوات والتقنيات الحديثة.
تاريخ وتطور الذكاء الاصطناعي حتى الآن
بدأ التفكير في الآلات القادرة على محاكاة التفكير منذ منتصف القرن العشرين. تطور المجال عبر مراحل أساسية: مرحلة القواعد المنطقية والأنظمة الخبيرة، ثم صعود الشبكات العصبية في الستينيات والسبعينيات، تلاها ركود مؤقت عندما كانت الموارد والبيانات غير كافية. في العقدين الأخيرين تحسّن الأداء بشكل جذري بفضل توفر بيانات ضخمة، قدرة حسابية أعلى (GPU/TPU)، وتطور خوارزميات تعلم الآلة وخاصة التعلم العميق. ظهرت نماذج متقدمة لمعالجة اللغة الطبيعية والرؤية الحاسوبية، ثم جاء تحول كبير مع نماذج الانتباه والترانسفورمرز التي أتاحت إنشاء نماذج لغوية قوية ونماذج متعددة المهام. إلى جانب ذلك ظهر اتجاه عملي لإدارة دورة حياة النماذج (MLOps) لتسهيل النشر والمراقبة.
النتيجة اليوم: تقنيات عملية وقابلة للتطبيق في مجالات صناعية وتجارية وطبية وتعليمية، مع سرعة نموٍ مستمرة في الأدوات والأساليب.
أنواع النماذج وأساليب التعلم
تقسم طرق التعلم والنماذج إلى أقسام عملية:
- التعلم الخاضع (Supervised Learning): يتعلم النموذج من أمثلة موسومة (مدخلات مع خروجيات معروفة). يستخدم في التصنيف والتنبؤ.
- التعلم غير الخاضع (Unsupervised Learning): يكتشف الأنماط أو التجمعات في بيانات غير موسومة، مثل تجزئة العملاء أو تقليل الأبعاد.
- التعلم شبه الخاضع (Semi-supervised): مزيج من النوعين السابقين، مفيد عندما تكون العلامات باهظة الثمن.
- التعلم التعزيزي (Reinforcement Learning): يتعلم وكيل من خلال تفاعل مع بيئة للحصول على مكافآت، يستخدم في الألعاب والتحكم الآلي.
- التعلّم العميق (Deep Learning): يعتمد على الشبكات العصبية متعددة الطبقات، مناسب لمعالجة الصور والنصوص والصوتيات.
اختيار النوع يعتمد على طبيعة المهمة والبيانات المتاحة وقيود المشروع.
البيانات: جمعها، تنظيفها، وتحضيرها
البيانات هي الأساس. خطوات التعامل معها:
- تحديد مصادر البيانات: قواعد بيانات داخلية، قواعد بيانات عامة، أجهزة استشعار، ملفات نصية، سجلات، أو خدمات خارجية عبر واجهات برمجية.
- جمع البيانات: استخدام سكربتات أو أدوات ETL أو جمع يدوي أو عبر واجهات برمجية. يجب الالتزام بقوانين الخصوصية عند جمع البيانات.
- تنظيف البيانات: إزالة القيم المفقودة أو التعامل معها، تصحيح القيم الشاذة، توحيد الصيغ، وإزالة التكرار.
- تحويل البيانات (Feature Engineering): استخراج أو إنشاء ميزات مفيدة من البيانات الخام مثل تجزئة النصوص، استخراج الإحصاءات من السلاسل الزمنية، أو تحويل الصور لأبعاد مناسبة.
- تقسيم البيانات: عادة إلى تدريب (70-80%)، تحقق (Validation 10-15%)، واختبار نهائي (10-15%).
- التوازن في التصنيفات: إذا كانت الفئات غير متوازنة، يمكن استخدام تقنيات إعادة أخذ العينات أو الوزن في دالة الخسارة.
أمثلة عملية: عند بناء نموذج لتصنيف أنواع نصوص، يتم تنظيف النص من علامات الترقيم، تحويل الحروف إلى حالة واحدة، إزالة الكلمات الشائعة غير المفيدة، ثم استخراج تمثيلات رقمية (مثل TF-IDF أو تمثيلات كلمات متجهية).
اختيار النموذج والخوارزميات
اختيار النموذج يعتمد على المهمة والبيانات والموارد. أمثلة عملية:
- مهام التصنيف البسيط: خوارزميات مثل Logistic Regression، Support Vector Machines، Decision Trees، Random Forest وGradient Boosting (مثل XGBoost, LightGBM) جيدة وفعالة على بيانات منظمة.
- التعامل مع النصوص: طرق تقليدية: Naive Bayes، TF-IDF مع خوارزميات بسيطة؛ طرق متقدمة: شبكات LSTM، CNN للنصوص، والترانسفورمرز مثل BERT وGPT.
- الصور والرؤية الحاسوبية: شبكات التلافيف CNN (مثل ResNet, EfficientNet)، ويمكن استخدام التعلم بالنقل مع نماذج مدربة مسبقاً.
- السلاسل الزمنية: نماذج ARIMA للتقليدية، ونماذج LSTM وTransformer للسلاسل الزمنية المعقدة.
نصيحة عملية: ابدأ بنموذج بسيط كخط أساس ثم اعمل تحسينات تدريجية. النماذج المعقدة ليست دائماً الأفضل إذا لم تكن البيانات كافية.
تدريب النموذج: العملية والأدوات
التدريب يتضمن إعداد دالة خسارة، مُحسّن (Optimizer) مثل SGD أو Adam، وعدد من الحقَب (Epochs) وحجم الدُفعات (Batch Size). خطوات عملية أساسية:
- تهيئة النموذج بالمعاملات الأولية (Weights initialization).
- تحديد دالة خسارة مناسبة (مثل cross-entropy للتصنيف، MSE للتنبؤ).
- اختيار المُحسّن وخفض معدل التعلم (Learning Rate scheduling) عند الحاجة.
- مراقبة الأداء على مجموعة التحقق لتجنب الإفراط في التعلّم (Overfitting).
- استخدام تقنيات منع الإفراط مثل التحقق المبكر (Early Stopping)، التنظيم (Regularization)، الإسقاط (Dropout).
أدوات عملية: مكتبات مثل TensorFlow وPyTorch، وأدوات أعلى مستوى مثل Keras. للعملية التجريبية يمكن استخدام أطر مثل Scikit-learn للنماذج التقليدية.
تقييم النموذج ومعايير الجودة
بعد التدريب نحتاج لتقييم فعالية النموذج باستخدام مقاييس مناسبة:
- التصنيف: الدقة (Accuracy)، الاسترجاع (Recall)، القياس (Precision)، مقياس F1، ومصفوفة الارتباك (Confusion Matrix).
- التنبؤ القيمي: متوسط الخطأ المطلق (MAE)، متوسط مربع الخطأ (MSE)، جذر متوسط مربع الخطأ (RMSE).
- المهام متعددة الفئات/متعددة الملصقات: استخدام مقاييس مناسبة لكل حالة وظيفية.
- التحقق المتقاطع (Cross-validation): لتقييم النموذج على أجزاء متعددة من البيانات والحصول على تقدير أفضل للأداء العام.
كما يجب مراقبة مؤشرات ثانوية مثل زمن الاستجابة واستهلاك الذاكرة خصوصًا عند النشر في بيئة إنتاج.
نشر النموذج وتشغيله في بيئة الإنتاج
بعد التأكد من كفاءة النموذج على بيانات الاختبار، يأتي دور النشر. خيارات النشر:
- خدمة عبر واجهة برمجية (REST API): إحضار النموذج داخل خادم ويب وتعرض واجهة API لاستقبال المدخلات وإرجاع النتائج.
- نشر على الحافة (Edge Deployment): تصغير النموذج وتشغيله على أجهزة متصلة مباشرة (مثل هواتف أو أجهزة إنترنت الأشياء).
- خدمات سحابية مُدارة: مثل منصات تقدم استضافة للنماذج مع مراقبة وتدرج تلقائي.
اعتبارات عملية: التحقق من أمان البيانات، مراقبة أداء النموذج بعد النشر، وجود نظام لإعادة التدريب أو التحديث الدوري عندما تتغير البيانات.
أحدث الأساليب والتقنيات العملية
في السنوات الأخيرة ظهرت تقنيات مهمة تُسهل الأداء وتحسن النتائج:
- الترانسفورمرز (Transformers): طورت نماذج معالجة اللغة الطبيعية وكانت لها تطبيقات في الرؤية الحاسوبية أيضًا. تُعتمد آلية الانتباه (Attention) لالتقاط العلاقات بين عناصر الدخل.
- التعلم الذاتي الإشراف (Self-supervised Learning): تدريب نماذج على مهام مختلفة بدون وسوم لتعلم تمثيلات قوية يمكن نقلها لمهام محددة.
- التعلم بالنقل (Transfer Learning): إعادة استخدام نموذج مدرب مسبقًا وتكييفه على مهمة جديدة ببيانات أقل.
- التقطيع والتقليص (Pruning & Quantization): لتقليل حجم النماذج وتسريعها عند النشر على الحافة.
- التقطيع المعرفي والنماذج الخفيفة (Distillation): تدريب نموذج أصغر "طالب" ليقلد نموذج أكبر "معلم" مع الحفاظ على أداء مقارب.
- MLOps وCI/CD للنماذج: أدوات وإجراءات لأتمتة التدريب، الاختبار، النشر، والمراقبة.
- التعلم الفيدرالي (Federated Learning): تدريب نماذج على بيانات موزعة عبر أجهزة مختلفة دون تجميع البيانات مركزيًا، مهم لحماية الخصوصية.
هذه الأساليب أصبحت معيارية في المشاريع المتقدمة لتسريع التطوير وتحسين التكلفة والسرعة.
تحسين الأداء وتقليل التكلفة
بعض النصائح العملية لتقليل التكلفة وتحسين الأداء:
- استخدم نماذج مُدربة مسبقًا: يوفر الوقت والتكلفة مقابل تدريب من الصفر.
- التعلم بالنقل: تكييف نموذج جاهز ببياناتك بدلاً من التدريب الكامل.
- تصغير النموذج: تقنيات مثل تقليل الدقة العددية (Quantization) أو تقليم الوصلات (Pruning) تقلل الذاكرة وزمن التنفيذ.
- استخدام خدمات سحابية حسب الحاجة: استئجار GPU لساعات التجريب بدلاً من شراء معدات باهظة.
- أتمتة التجارب ومراقبة التكلفة: سجّل استخدام الموارد لكل تجربة لتحديد الأنسب من حيث الأداء والتكلفة.
مثال عملي مفصّل: بناء نموذج تصنيف نصي مبسط
فيما يلي خطوات عملية لبناء نموذج بسيط لتصنيف نصوص (مثلاً: تصنيف مواضيع مقالات إلى فئات محددة):
- تجميع البيانات: جمع نصوص موسومة بكل فئة. مثال: مجموعة نصوص لكل فئة موضوعية.
- تنظيف النصوص: إزالة علامات الترقيم، تحويل الحروف، إزالة كلمات التوقف، واستبدال الأرقام برمز موحد إن لزم.
- تمثيل النص عدديًا: استخدام TF-IDF أو تمثيلات كلمات متجهية مثل Word2Vec أو استخدام نموذج مسبق مثل BERT لاستخراج تمثيلات الجمل.
- اختيار نموذج: ابدأ بـ Logistic Regression أو Random Forest كخط أساس. ثم جرب نموذج تحويل مثل BERT مع طبقة تصنيف أخيرة لتحسين النتائج.
- تدريب وتقييم: استخدم تقسيم 80/10/10، راقب دقة الفئة ومقياس F1، واستخدم التحقق المتقاطع إن أمكن.
- تحسين: جرب ضبط المعلمات (Hyperparameter tuning) مثل معدل التعلم، حجم الدفعة، وعدد الطبقات في حالة الشبكات العصبية.
- نشر: تحويل النموذج إلى واجهة REST بسيطة يمكن للتطبيقات استدعاؤها وإرجاع التوقعات.
مثال مبسّط لفهم مفهوم دالة الخسارة Backpropagation: تخيل أن لديك نموذجًا يتنبأ بقيمة رقمية. بعد كل دفعة، تقارن التوقع بالحقيقة وتحسب مقدار الخطأ. ثم تُرجع هذا الخطأ للخلف عبر الشبكة لتعدل الأوزان بحيث يقل الخطأ في المستقبل. هذه العملية تكرارية وتستمر عبر الحقب حتى يتحسن الأداء.
البنية التحتية والتكاليف المتوقعة
تقدير التكاليف يعتمد على حجم المشروع:
- مرحلة التعلم والتجربة: إمكانية البدء على جهاز شخصي؛ استخدام خدمات مجانية مثل منصات الحوسبة التشاركية لتجارب صغيرة. تكلفة مادية تقريبية: صفر إلى بضع دولارات يوميًا عند استخدام خدمات سحابية مدفوعة ساعية.
- مرحلة التطوير المتقدم: حاجة إلى GPU جيدة أو استئجار مثيل GPU على السحابة. تكاليف سحابية تتراوح من بضع دولارات إلى عشرات الدولارات في الساعة بحسب نوع الجهاز.
- مرحلة الإنتاج: احتياج لاستضافة ثابتة، تدرج تلقائي، ومراقبة. تكلفة شهرية قد تتراوح من مئات إلى آلاف الدولارات للمشروعات المتوسطة حسب الاستخدام.
عوامل تؤثر على التكلفة: عدد النماذج المدربة، تكرار إعادة التدريب، حجم البيانات المخزنة، زمن الاستجابة المطلوب، وعدد المستخدمين الذين سيستهلكون الخدمة.
المسؤولية والأخلاقيات والاعتبارات القانونية
عند بناء نماذج، يجب مراعاة:
- الخصوصية: حماية بيانات المستخدمين والالتزام بقوانين حماية البيانات المحلية والدولية.
- التحيز والإنصاف: اختبار بيانات التدريب لضمان عدم وجود تحيزات قد تؤدي لقرارات غير عادلة.
- القابلية للتفسير: في بعض التطبيقات الحساسة مطلوب أن يكون النموذج قابلًا للتفسير لتوضيح قراراته.
- الأمان: حماية النموذج من هجمات التسميم أو هجمات استغلال ثغرات في النظام.
- المسؤولية القانونية: التأكد من الاستخدام القانوني للبيانات والنماذج ووجود اتفاقيات واضحة حول المسؤوليات.
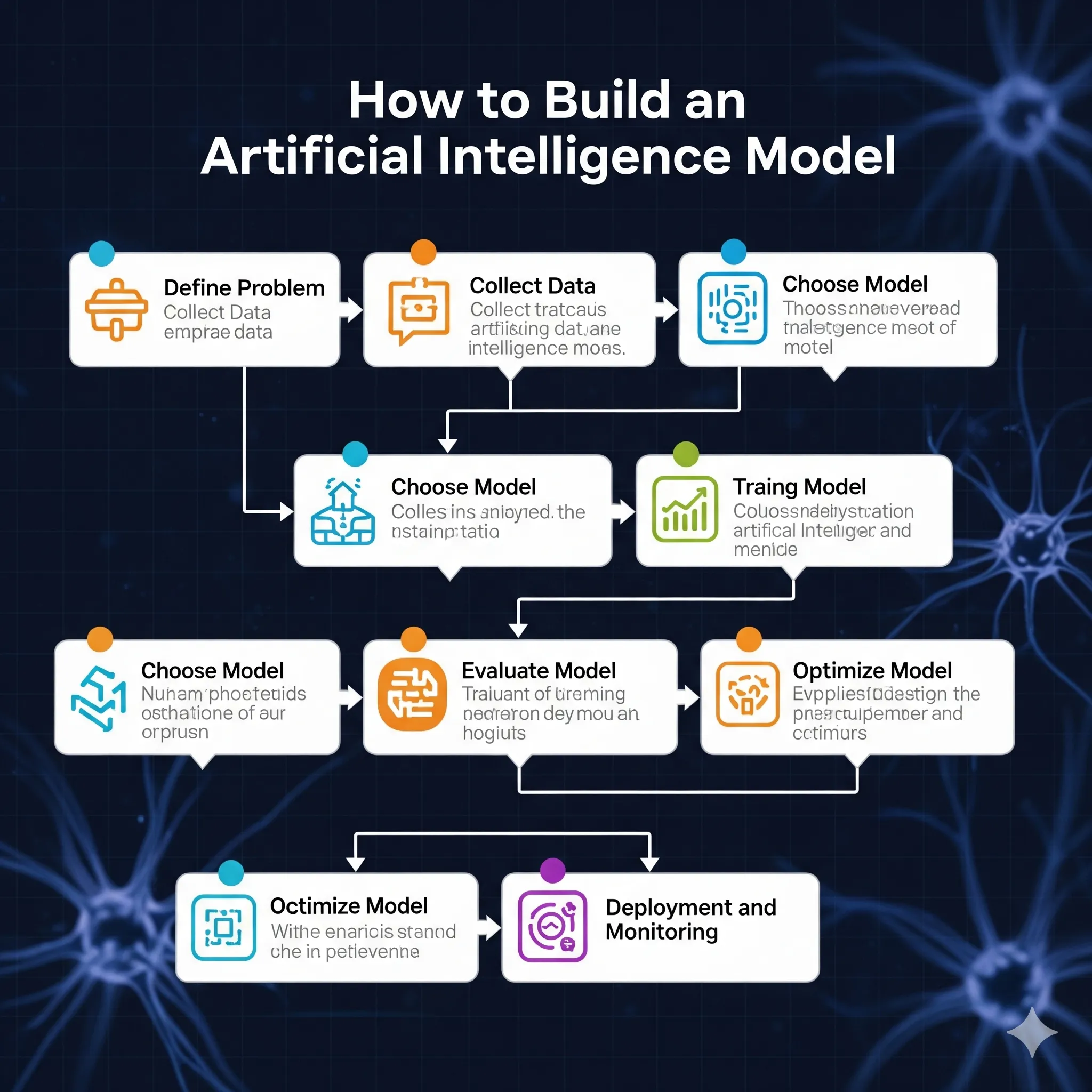
خطة خطوة بخطوة لبناء أول نموذج عملي
خريطة طريق عملية للمبتدئين:
- تحديد الهدف بوضوح (ماذا سيحل النموذج؟).
- جمع عينة صغيرة من البيانات وتجهيزها.
- بناء نموذج بسيط كخط أساس وتقييمه.
- تحسين الميزات والنموذج تدريجياً.
- التدرج إلى نماذج أعقد عند الحاجة مع مراقبة التكلفة.
- إعداد خطط لنشر النموذج ومراقبته وإعادة تدريبه عندما تتغير البيانات.
نقاط عملية: احتفظ بسجل لكل تجربة، استخدم أنظمة إدارة إصدار للنماذج والبيانات، وابدأ بنماذج بسيطة لتفهم المشكلات قبل تعقيد الحلول.
الخلاصة والمراجع المقترحة للمتابعة
بناء نموذج ذكاء اصطناعي عملية متكاملة تبدأ بتحديد هدف واضح، مرورًا بجمع وتحضير بيانات جيدة، اختيار النموذج المناسب وتدريبه، ثم تقييمه ونشره ومراقبته. التطور السريع في الأدوات والأساليب يجعل البدء أسهل من أي وقت مضى، ولكن التحديات الحقيقية تكمن في جودة البيانات، التصميم المنطقي للميزات، والاعتبارات الأخلاقية والقانونية.
مصادر توجيهية للتعلم (مقترحات عامة): دروس عملية على منصات تعليمية، توثيق مكتبات مثل TensorFlow وPyTorch، ودورات متخصصة في MLOps والتعلم العميق. البدء بمشروع صغير وتجريبي سيساعد على فهم كامل للخطوات ثم التوسع تدريجيًا.